价值分解网络 (VDN)¶
论文链接:
今天,我们介绍 VDN(价值分解网络)算法。我原本计划与 QMIX 一起介绍这个算法,但考虑到 VDN 在 MARL 领域的声誉和影响力,我决定先单独介绍这个算法。此外,作为 QMIX 的前身,对 VDN 算法的深入分析应该有助于我们更全面地理解 QMIX 算法。通过这种方式,我们也可以更全面地了解这两种算法的优缺点。
下表列出了 VDN 算法的一些一般特性:
VDN 的特性 |
值 |
描述 |
|---|---|---|
完全去中心化 |
❌ |
智能体之间没有通信。 |
完全中心化 |
❌ |
智能体将所有信息发送给中央控制器,控制器将为所有智能体做出决策。 |
中心化训练与去中心化执行(CTDE) |
✅ |
在训练中使用中央控制器,在执行中放弃。 |
同策略 |
❌ |
评估策略与目标策略相同。 |
异策略 |
✅ |
评估策略与目标策略不同。 |
无模型 |
✅ |
不需要准备环境动力学模型。 |
基于模型 |
❌ |
需要环境模型来训练策略。 |
离散动作 |
✅ |
处理离散动作空间。 |
连续动作 |
❌ |
处理连续动作空间。 |
I. 问题背景与研究方法¶
与 COMA 类似,这项工作解决了协作任务中的多智能体强化学习问题,意味着所有智能体共享相同的奖励值(也称为团队奖励)。区别在于 VDN 是基于价值函数的方法,而 COMA 基于策略梯度。在之前对 COMA 的介绍中,我们提到智能体共享团队奖励会导致”信用分配”问题——即使用此团队奖励拟合的价值函数无法评估每个智能体的策略对整体结果的贡献。本文也存在这个问题。
作者认为,由于每个智能体只有局部观测,一个智能体获得的团队奖励很可能是由其队友的动作引起的。换句话说,这个奖励对该智能体来说是一个”虚假奖励信号”。因此,每个智能体使用强化学习算法(即独立 RL)独立学习通常会产生较差的性能。
虚假奖励还伴随着作者称为”懒惰智能体”的现象。当团队中的一些智能体学习了有效策略并能够完成任务时,其他智能体可以在不采取重大动作的情况下获得有利的团队奖励——这些智能体被称为”懒惰智能体”。
本质上,”虚假奖励”和”懒惰智能体”都源于信用分配问题。如果每个智能体根据其对团队的实际贡献来优化自己的目标函数,上述问题就可以解决。在这种动机的驱动下,作者提出了一种以”价值函数分解”为中心的研究方法,将团队的全局价值函数分解为 N 个子价值函数。这些子价值函数然后作为每个智能体动作选择的基础。
II. 算法设计¶
考虑到上述方法,下一步是找出如何分解价值函数。在这里,作者采用了最简单的方法:求和。
2.1 Q 函数价值分解¶
假设 \(Q((h^1, h^2, \cdots, h^d), (a^1, a^2, \cdots, a^d))\) 是多智能体团队的全局 Q 函数,其中 \(d\) 是智能体数量,\(h^i\) 是智能体 \(i\) 的历史序列信息,\(a^i\) 是其动作。该 Q 函数的输入包含所有智能体的观测和动作,可以通过团队奖励 \(r\) 迭代拟合。为了推导每个智能体的价值函数,作者提出以下假设:
这个假设表明,团队的 Q 函数可以通过求和近似分解为 \(d\) 个子 Q 函数,每个对应于 \(d\) 个不同的智能体,每个子 Q 函数的输入包括其对应智能体的局部观测序列和动作,并且这些子 Q 函数彼此不受影响,如下图所示。
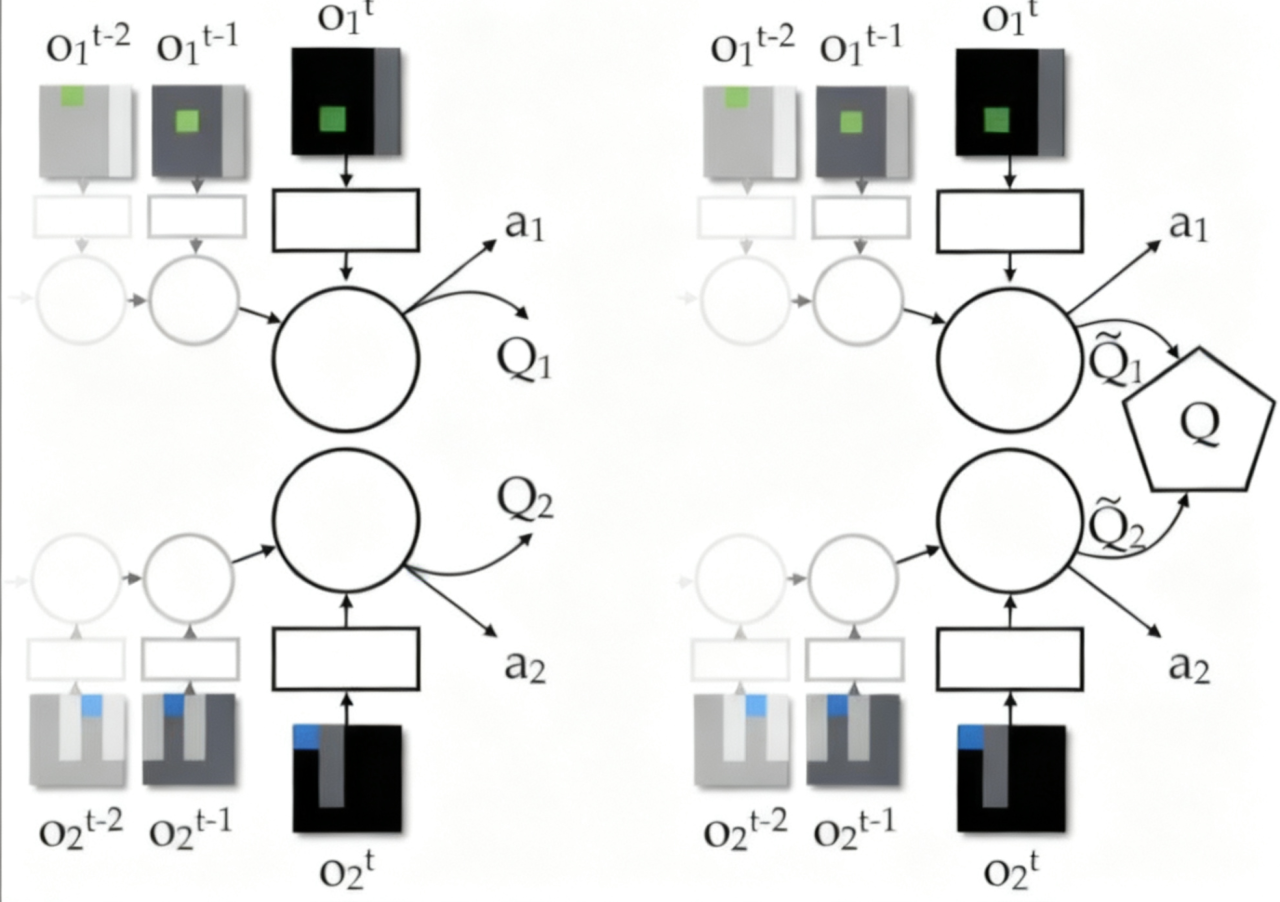
Figure 1. 左:独立 RL;右:VDN 价值分解。¶
因此,每个智能体都有自己的价值函数,可以基于其局部价值函数做出决策:
注意:这里,\(\tilde{Q}_i (h^i, a^i)\) 在任何严格意义上都不是 Q 值函数,因为没有理论保证一定存在使这个 \(\tilde{Q}_i\) 满足贝尔曼方程的奖励函数。
2.2 这种分解是否合理?¶
实际上,要使公式 (1) 成立,至少必须满足一个条件:
其中 \(\mathbf{s}\) 表示系统的全局状态,\(\mathbf{a}\) 表示所有智能体的联合动作。公式 (3) 表明,团队的全局奖励应该通过对所有智能体的个体奖励函数求和获得。然而,即使满足这个条件,根据论文中的证明,Q 函数的分解应该写为: \(Q(\mathbf{s}, \mathbf{a}) = \sum_{i=1}^d Q_i(\mathbf{s}, \mathbf{a})\)。 每个子 Q 函数的输入应该是全局状态 \(\mathbf{s}\) 和联合动作 \(\mathbf{a}\),而不是公式 (1) 中的形式。
因此,这个缺陷是 VDN 算法的根本局限性,为了补偿局部观测的约束,作者使用每个智能体的历史观测、动作和奖励序列作为其价值函数 \(\tilde{Q}_i\) 的输入。
尽管如此,这种设置确保每个智能体不共享相同的价值函数,这在一定程度上缓解了信用分配问题。
此外,VDN 的结构支持端到端训练。在中心化训练期间,VDN 只需要计算全局 Q 函数的 TD 误差,然后将误差反向传播到每个单独的 Q 函数,大大降低了计算复杂度。
2.3 参数共享¶
与 COMA 算法类似,为了减少训练参数,作者还考虑了在智能体之间共享参数。参数共享的一个优势是它可以防止懒惰智能体的出现。为了证明参数共享的合理性,作者提供了”智能体不变性”的定义:
定义 1(智能体不变性):对于智能体索引的任何置换 \( p : \{1, \cdots, d\} \rightarrow \{1, \cdots, d\} \),其中 \(p\) 是双射,如果 \( \pi(p(\bar{h})) = p(\pi(\bar{h})) \) 成立,我们说 \(\pi\) 具有”智能体不变性”。(这里, \(\bar{h} := (h^1, h^2, \cdots, h^d)\))
“智能体不变性”表明,交换智能体的观测顺序等价于交换智能体的策略顺序。换句话说,所有智能体具有相等的地位和相似的功能。然而,当环境包含异构智能体或需要为智能体分配不同角色时,”智能体不变性”是不必要的。如果智能体共享网络参数,每个智能体的动作输出将依赖于该智能体的观测和索引。这方面类似于 COMA。
总结¶
VDN 算法具有简单的结构,通过其分解获得的 \(Q_i\) 允许智能体基于其局部观测选择贪婪动作,从而执行分布式策略。其中心化训练方法在一定程度上确保了全局 Q 函数的最优性。此外,VDN 的”端到端训练”和”参数共享”使算法收敛非常快,对于某些简单任务,该算法可以被认为是既快速又有效的。
然而,对于更大规模的多智能体优化问题,其学习能力显著降低。根本局限性在于缺乏对价值函数分解有效性的理论支持。VDN 通过简单的求和方法完全分解全局 Q 函数,这大大限制了多智能体 Q 网络的拟合能力。
在接下来要介绍的 QMIX 算法中,继续采用这种端到端训练方法。作者通过合并系统的全局状态信息并对去中心化策略施加单调性约束,改进了价值函数分解的网络架构,从而有效增强了网络近似全局 Q 函数的能力。
在 XuanCe 中运行 VDN¶
在 XuanCe 中运行 VDN 之前,您需要准备 conda 环境并按照
安装步骤 安装 xuance。
运行内置演示¶
完成安装后,您可以打开 Python 控制台并使用以下命令直接运行 VDN:
import xuance
# 为 VDN 算法创建运行器
runner = xuance.get_runner(method='vdn',
env='sc2', # 选择:sc2, mpe, robotic_warehouse, football
env_id='3m', # 选择:3m, 2m_vs_1z, 8m, 1c3s5z, 2s3z, 25m, 5m_vs_6m, 8m_vs_9m, MMM2 等。
is_test=False) # False 用于训练,True 用于测试
runner.run() # 开始运行(或 runner.benchmark() 用于基准测试)
使用自定义配置运行¶
如果您想使用不同的配置运行 VDN,可以创建一个新的 .yaml 文件,例如 my_config.yaml。
然后,通过以下代码块运行 VDN:
import xuance as xp
# 为 VDN 算法创建运行器
runner = xp.get_runner(method='vdn',
env='sc2', # 选择:sc2, mpe, robotic_warehouse, football
env_id='3m', # 选择:3m, 2m_vs_1z, 8m, 1c3s5z, 2s3z, 25m, 5m_vs_6m, 8m_vs_9m, MMM2 等。
config_path="my_config.yaml", # my_config.yaml 文件的路径应该是正确的。
is_test=False) # False 用于训练,True 用于测试
runner.run() # 开始运行(或 runner.benchmark() 用于基准测试)
使用自定义环境运行¶
如果您想在 XuanCe 中未包含的自己的环境中运行 XuanCe 的 VDN,
您需要按照
新环境教程 中的步骤定义新环境。
然后,准备配置文件
vdn_myenv.yaml。
之后,您可以使用以下代码在自己的环境中运行 VDN:
import argparse
from xuance.common import get_configs
from xuance.environment import REGISTRY_MULTI_AGENT_ENV
from xuance.environment import make_envs
from xuance.torch.agents.multi_agent_rl.vdn_agents import VDN_Agents
configs_dict = get_configs(file_dir="VDN_myenv.yaml")
configs = argparse.Namespace(**configs_dict)
REGISTRY_MULTI_AGENT_ENV[configs.env_name] = MyNewEnv
envs = make_envs(configs) # 创建并行环境。
Agent = VDN_Agents(config=configs, envs=envs) # 从 XuanCe 创建 VDN 智能体。
Agent.train(configs.running_steps // configs.parallels) # 训练模型多个步骤。
Agent.save_model("final_train_model.pth") # 将模型保存到 model_dir。
Agent.finish() # 完成训练。
引用¶
@misc{sunehag2017valuedecompositionnetworkscooperativemultiagent,
title={Value-Decomposition Networks For Cooperative Multi-Agent Learning},
author={Peter Sunehag and Guy Lever and Audrunas Gruslys and Wojciech Marian Czarnecki and Vinicius Zambaldi and Max Jaderberg and Marc Lanctot and Nicolas Sonnerat and Joel Z. Leibo and Karl Tuyls and Thore Graepel},
year={2017},
eprint={1706.05296},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/1706.05296}
}
@inproceedings{sunehag2018valuedecomposition,
title = {Value-Decomposition Networks For Cooperative Multi-Agent Learning Based on Team Reward},
author = {Sunehag, Peter and Lever, Guy and Gruslys, Audrunas and Czarnecki, Wojciech Marian and Zambaldi, Vinicius and Jaderberg, Max and Lanctot, Marc and Sonnerat, Nicolas and Leibo, Joel Z. and Tuyls, Karl and Graepel, Thore},
booktitle = {Proceedings of the 17th International Conference on Autonomous Agents and MultiAgent Systems (AAMAS)},
year = {2018},
pages = {2085--2087},
publisher = {International Foundation for Autonomous Agents and Multiagent Systems}
}